Allgemein
Hier kannst du globale SEO-Funktionen und Debugging-Optionen steuern.
Experimentelle SEO Einstellungen aktivieren
Aktiviere diesen Schalter, um Zugriff auf neue, noch in der Entwicklung befindliche SEO-Features zu erhalten (siehe Abschnitt “Experimentelle Funktionen” weiter unten).DEBUG MODE
Aktiviere diese Option, um Konsolenausgaben zu den SEO-Einstellungen im Browser zu erhalten. Dies ist hilfreich zur Fehleranalyse.Robots Text
Der Robots Text weist Suchmaschinen Crawler an, dass sie eine Seite indexieren und den Links auf der Seite folgen sollen oder nicht. Es ist eine Empfehlung, kein Muss. Dennoch ist es sinnvoll manche Seitentypen durch diese Anweisungen von der Indexierung mancher Seiten auszuschließen. Einige Seiten kannst du über die Shopeinstellungen direkt ausschließen. Diese erhalten dann die Variable\$noIndex = true. Andere Arten wie Paginationen oder aktive Filterseiten haben diese Option nicht. Du kannst hier für alle diese Typen eigene Robots Anweisungen hinterlegen und priorisieren.
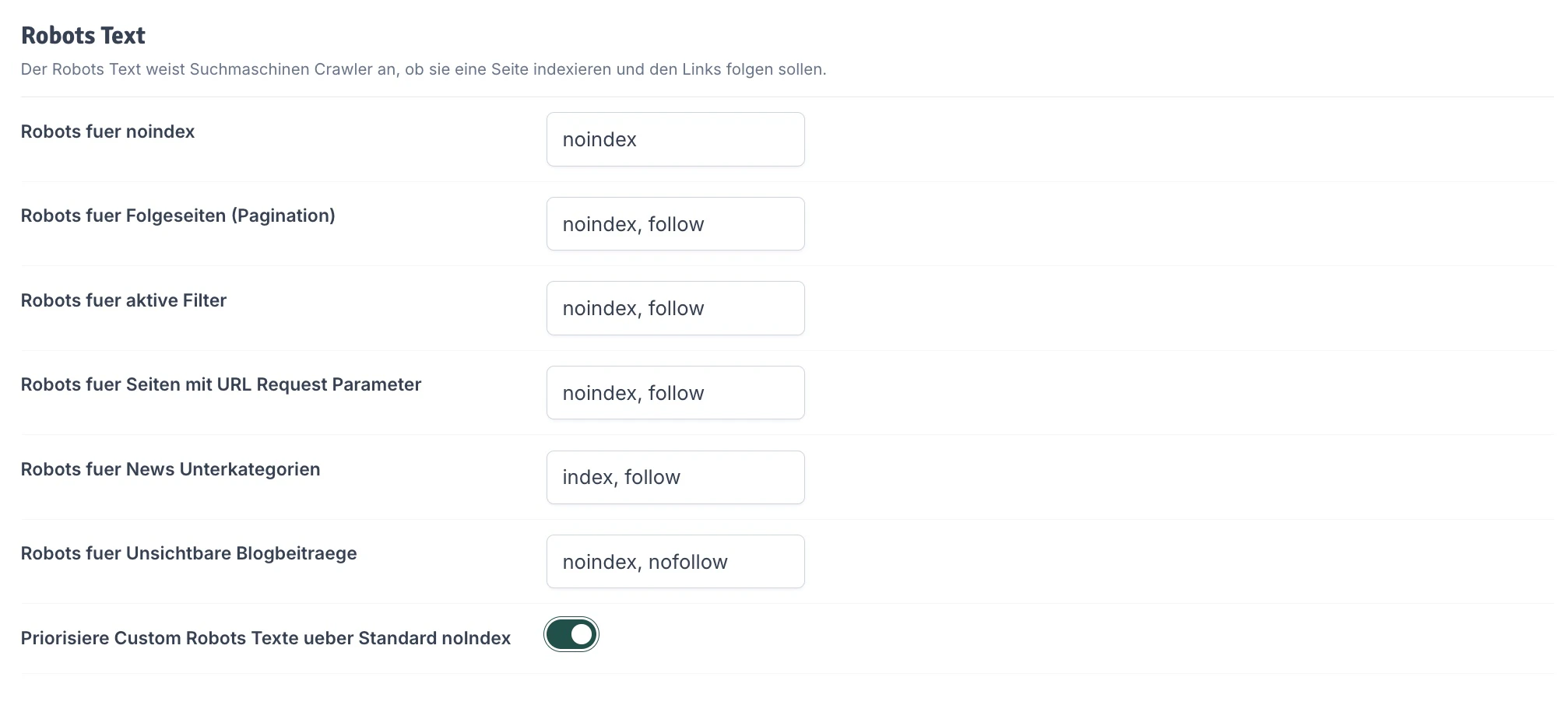
- Robots für noindex: Lege eine Regel für Seiten fest, die per Variable
$noIndexausgeschlossen wurden. - Robots für Folgeseiten (Pagination): Steuere das Indexierungsverhalten auf Seite 2, 3 usw. von Artikellisten.
- Robots für aktive Filter: Definiere Regeln für Artikellisten, auf denen Filter aktiv sind (oft Duplicate Content).
- Robots für Seiten mit URL Request Parameter: Lege Regeln für URLs mit Parametern fest.
- Robots für News Unterkategorien: Spezielle Regeln für Blog-Kategorien.
- Robots für unsichtbare Blogbeiträge: Steuere die Sichtbarkeit von internen oder versteckten Beiträgen.
- Priorisiere Custom Robots Texte über Standard noindex: Wenn aktiviert, überschreiben deine Einstellungen hier die JTL-Standards.
Canonical Tag
Das Canonical Tag zeigt Suchmaschinen an, dass es sich bei der aktuellen Seite um ein Original oder um eine Variante einer existierenden Seite handelt. Dadurch verhindert man, dass Suchmaschinen deinen Inhalt als doppelten Content werten. Die Empfehlung geht dahin, dass Seiten, die nicht indexiert werden sollen auch kein Canonical Tag benötigen. Das kannst du hier festlegen.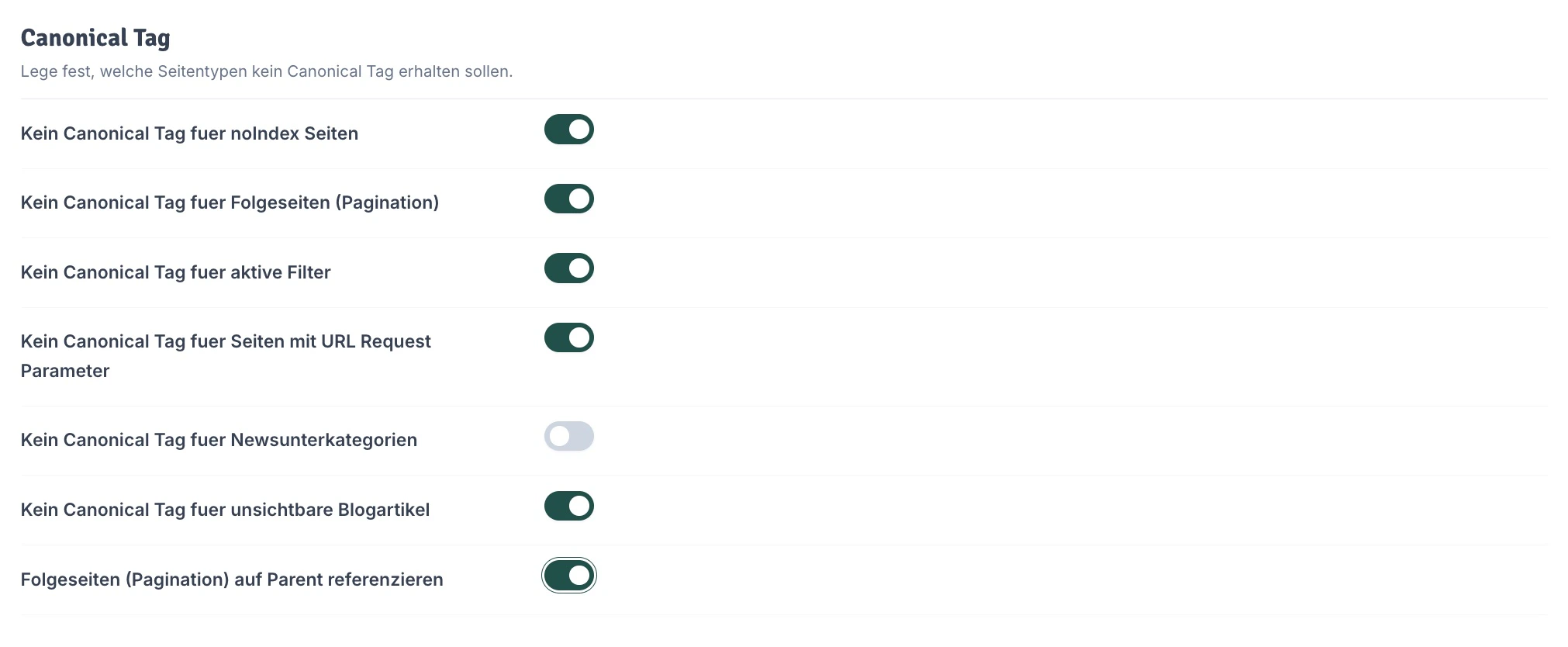
- Kein Canonical Tag für noindex Seiten: Empfohlen: An (da nicht indexierte Seiten kein Canonical benötigen).
- Kein Canonical Tag für Folgeseiten (Pagination): Empfehlung: An, Standard: Aus.
- Kein Canonical Tag für aktive Filter: Empfehlung: An, Standard: Aus.
- Kein Canonical Tag für Seiten mit URL Request Parameter: Empfehlung: An, Standard: Aus.
- Kein Canonical Tag für Newsunterkategorien: Nur sinnvoll, wenn noindex verwendet wird. Unverbindliche Empfehlung: Aus, Standard: Aus.
- Kein Canonical Tag für unsichtbare Blogartikel: Empfehlung: An, Standard: Aus.
- Folgeseiten (Pagination) auf Parent referenzieren: Setzt den Canonical Link von Seite 2, 3 etc. auf die Hauptkategorie (Seite 1). Empfehlung: An, Standard: Aus.
Alternate Hreflang
Alternate Hreflang zeigt auf jeder Seite auf den Link der jeweiligen Sprachversion und der gesetzten Standardsprache, wenn keine passende Sprache für den Seitenbesucher zur Verfügung steht. Die Empfehlungen gehen dahin, dass Seiten, die nicht indexiert werden sollen, auch kein hreflang ausweisen sollen.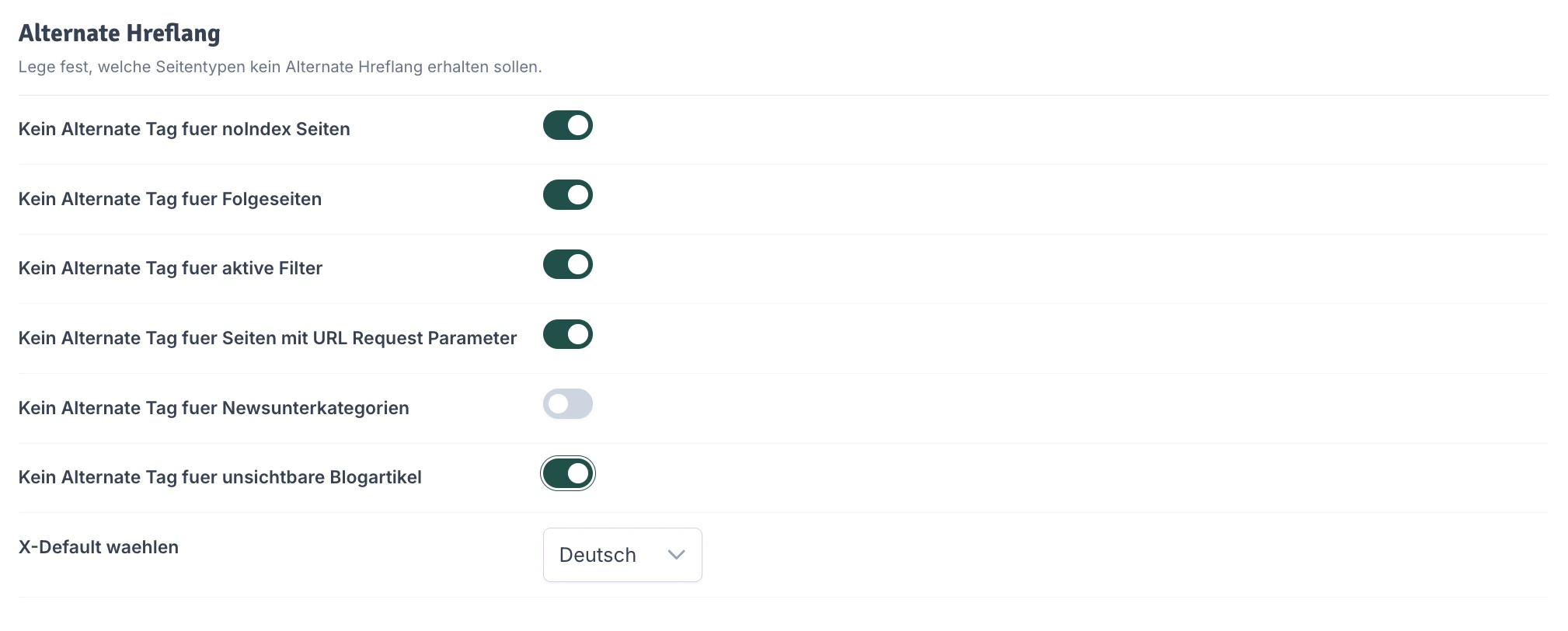
- Kein Alternate Tag für noindex Seiten: Empfehlung: An, Standard: Aus.
- Kein Alternate Tag für Folgeseiten (Pagination): Empfehlung: An, Standard: Aus.
- Kein Alternate Tag für aktive Filter: Empfehlung: An, Standard: Aus.
- Kein Alternate Tag für Seiten mit URL Request Parameter: Empfehlung: An, Standard: Aus.
- Kein Alternate Tag für Newsunterkategorien: Nur sinnvoll, wenn noindex verwendet wird. Unverbindliche Empfehlung: Aus, Standard: Aus.
- Kein Alternate Tag für unsichtbare Blogartikel: Empfehlung: An, Standard: Aus.
- X-Default wählen: Hier kannst du unabhängig von der Standardsprache deines Shops eine Sprache auswählen, die als X-Default verwendet wird. Browser können anhand der Sprachen für den User die passende Sprachversion anzeigen. Wenn es keine passende Sprache gibt, wird die X-Default als Standardsprache bevorzugt ausgegeben. In den meisten Fällen ist es sinnvoll die englische Version standardmäßig anzubieten. Da viele Shops aber standardmäßig auf deutsch eigestellt sind, bieten wir hier eine Möglichkeit den X-Default Wert selbst festzulegen, ohne die Standardsprache des Shops ändern zu müssen.
Linkmaskierung [BETA]
Durch die Linkmaskierung werden alle Links für Filterauswahl, Sortierung und Layout so unkenntlich gemacht, dass sie für Crawler nicht direkt als Links identifiziert werden. Dadurch kann verhindert werden, dass entsprechend parametrisierte Seiten überhaupt von Suchmaschinen indexiert werden, weil die Crawler diesen Pseudolinks gar nicht erst folgen, was sich wiederum positiv auf das Crawlingverhalten auswirken kann. Grund ist, dass manche Crawler trotz nofollow Anweisung dennoch den Links auf der Seite folgen und parametrisierte Seiten dennoch indexiert werden. Der gewünschte Vorteil wäre, dass das Crawlbudget effektiver in Hauptseiten investiert wird.
- Linkmaskierung aktivieren: Schaltet die Umwandlung in Pseudolinks ein.
Graph based LD+JSON für strukturierte Daten
JTL verwendet standardmäßig das inline Markup für die Auszeichnung strukturierter Daten. Diese sind zum Teil schwer wartbar, teilweise unvollständig und schlecht erweiterbar. Wir bieten dir hier die Möglichkeit die Strukturierten Daten per LD+JSON, einem JSON-ähnlichen, gut strukturierten Format zur Verfügung zu stellen. Das Format ist maschinen-freundlich für Crawler und KI. Bitte beachte, dass Suchmaschinen-Crawler erwarten, dass strukturierte Daten aus LD+JSON auch valide sind. Reichere deine Daten nicht mit widersprüchlichen Informationen an.
Strukturierte Daten (Graph) – Optionen
Dieser Abschnitt erscheint nur, wenn Graph based LD+JSON verwenden aktiviert ist.
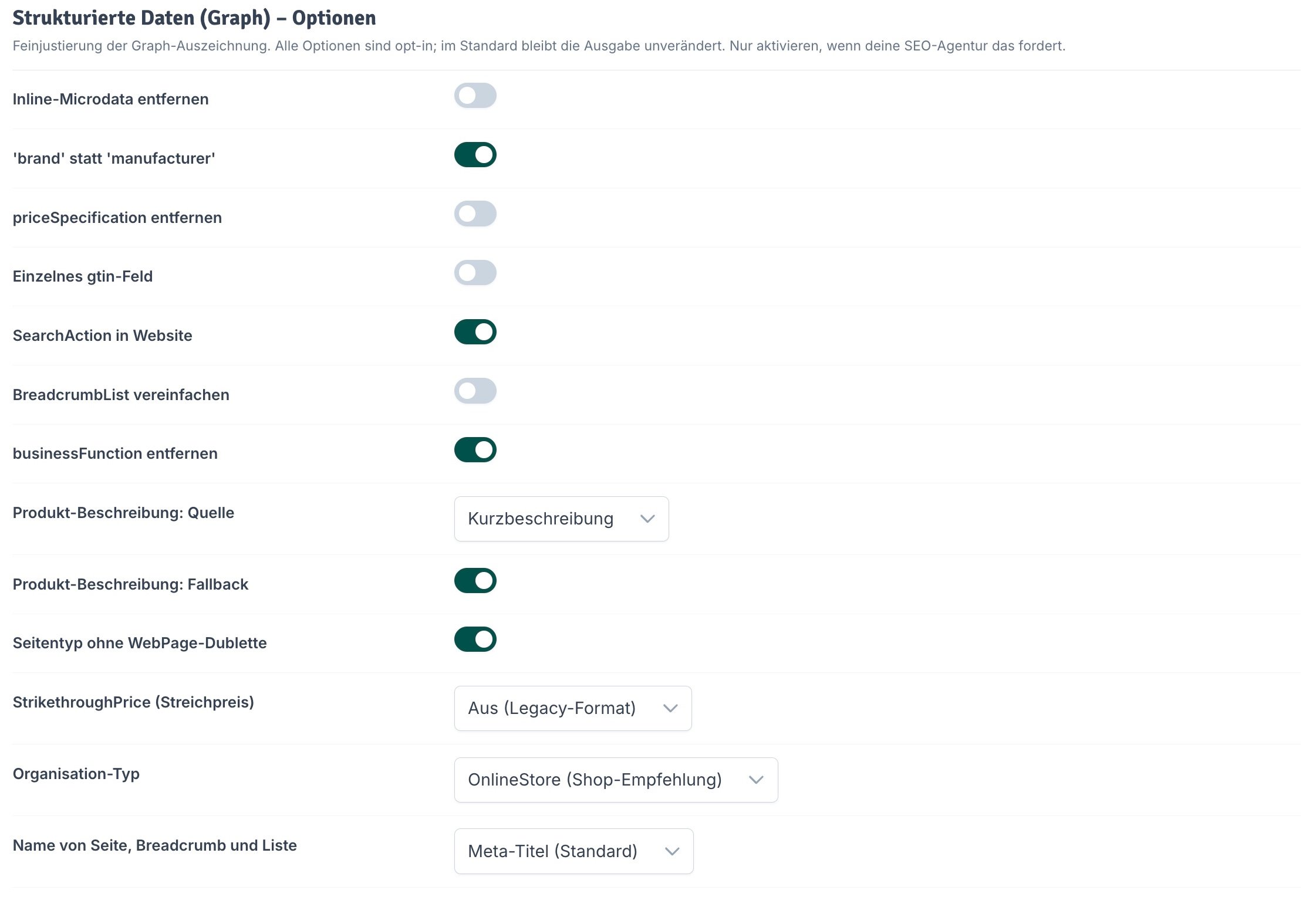
- Inline-Microdata entfernen: Entfernt das JTL-Standard Inline-Markup, sodass nur noch die Graph-Daten per LD+JSON ausgegeben werden.
- ‘brand’ statt ‘manufacturer’: Gibt die Marke im Feld
brandstattmanufactureraus. - priceSpecification entfernen: Entfernt die detaillierte
priceSpecificationaus den Produktdaten. - Einzelnes gtin-Feld: Gibt die GTIN in einem einzelnen
gtin-Feld statt in den spezifischen Feldern (gtin8,gtin12,gtin13,gtin14) aus. - SearchAction in Website: Ergänzt die Website-Auszeichnung um eine
SearchActionfür die Sitelinks-Suchbox. - BreadcrumbList vereinfachen: Reduziert die Breadcrumb-Auszeichnung auf die notwendigen Kernfelder.
- businessFunction entfernen: Entfernt das Feld
businessFunctionaus dem Angebot (Offer). - Produkt-Beschreibung: Quelle: Wähle, ob als Produktbeschreibung im Graph die Kurzbeschreibung oder die Langbeschreibung verwendet wird (Standard: Kurzbeschreibung).
- Produkt-Beschreibung: Fallback: Lege eine Ersatzquelle fest, falls die gewählte Beschreibung leer ist.
- Seitentyp ohne WebPage-Dublette: Verhindert, dass für spezifischere Seitentypen (z. B. Produkt, Artikelliste) zusätzlich der generische Typ
WebPageausgegeben wird. - StrikethroughPrice (Streichpreis): Lege fest, wie ein Streichpreis ausgezeichnet wird (Standard: Aus (Legacy-Format)).
- Organisation-Typ: Wähle den Schema.org-Typ für dein Unternehmen (Standard: OnlineStore (Shop-Empfehlung)).
- Name von Seite, Breadcrumb und Liste: Lege fest, welcher Wert als Name verwendet wird (Standard: Meta-Titel).
Mehr Infos
Warum Graph based? “Graph based” bedeutet, dass Beziehungen zwischen einzelnen Elementen hergestellt werden. Crawler verstehen so die Semantik und Zusammenhänge besser, was insbesondere für KI-Anwendungen von Vorteil ist.
Hinweis zu Testing Tools: Es ist normal, dass Daten in Testing Tools doppelt auftauchen (einmal als JTL-Standard Microdata und einmal als LD+JSON). Das ist laut Google unbedenklich und valid.
FAQ
LD+JSON
JTL verwendet standardmäßig das inline Markup für die Auszeichnung strukturierter Daten. Diese sind zum Teil schwer wartbar, teilweise unvollständig und schlecht erweiterbar. Wir bieten dir hier die Möglichkeit die Strukturierten Daten per LD+JSON, einem JSON-ähnlichen, gut strukturierten Format zur Verfügung zu stellen. Bitte beachte, dass Suchmaschinen-Crawler erwarten, dass strukturierte Daten aus LD+JSON auch visuell auf der Seite repräsentiert werden. Daher tauchen im LD+JSON nur Daten auf, die auch sichtbar sind. Es ist nicht gestattet die Datensätze künstlich anzureichern und Suchmaschinen können solche Versuche hart abstrafen.
- LD+JSON für den Typ Organisation verwenden: Strukturierte Daten über dein Unternehmen.
- LD+JSON für den Typ Website verwenden: Strukturierte Daten für die Website selbst.
- LD+JSON für den Typ Breadcrumb verwenden: Strukturierte Daten für die Navigationsstruktur.
- LD+JSON für Produktlisten aus Kategorie und Suchergebnissen verwenden: Die Einstellungen hier beziehen sich auf jegliches Produktlisting, zB Kategorieseiten und auch Standardslider wie CrossSelling, Bestseller etc. Aktuell werden nur Produktlisten der Artikelkategorien und Suchergebnisse unterstützt. Die Funktion wird aber ausgeweitet. Bitte beachte, dass das inline Markup weiterhin aktiv bleibt, sodass du beim Testen neben den LD+JSON Werten auch Einträge aus dem Inline Markup sehen wirst. Das LD+JSON dient der einfacheren Indexierung und Anreicherung mit Daten.
- LD+JSON für Produkt auf Produktdetailseite: Strukturierte Daten für einzelne Artikel.
- LD+JSON für News Artikel: Strukturierte Daten für Blogbeiträge.